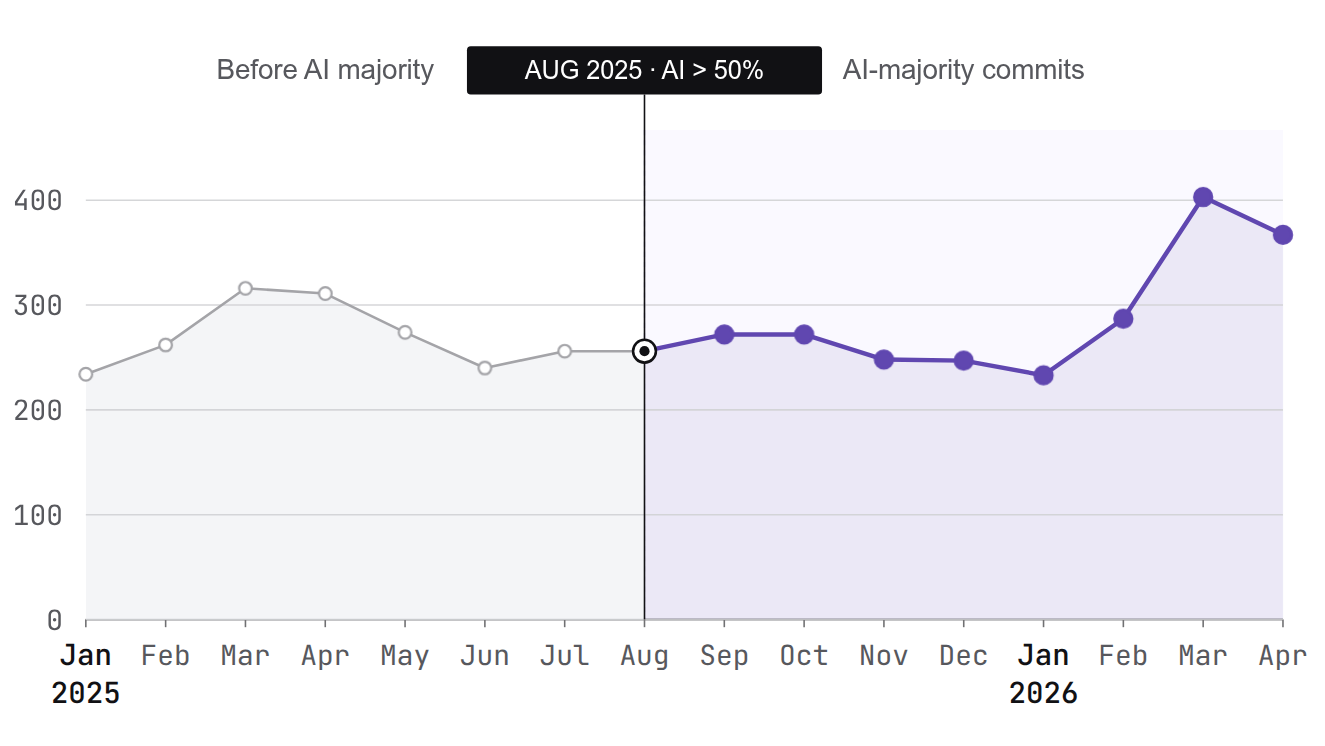
Since August 2025, more than half of the new code hitting Ashby’s production systems has been AI-generated, yet customer issues didn't suddenly spike. See the graph below. More than double the customers. 60% more engineers. More AI-written code. The sky didn’t fall.
This isn't an AI hype piece. It's a not a hit piece either. We got here by being balanced.
We have a blip in March / April every year. We've noticed them annually and we haven't yet found a solid reason why. There’s no correlation with customer growth, PRs shipped, or features shipped. It's likely a combination of various seasonal effects in our own hiring and customer onboarding. Cursor provides stats on how much of our code is generated by AI.
We’ve also not seen any regressions in code quality, velocity, or onboarding time for engineers (anecdotally, we’ve seen comprehension of the codebase increase!).
This isn’t a toy project. Ashby is a suite of talent acquisition software with over 100,000 weekly active users, millions of candidate applications per week, and features that resemble entire companies' worth of product (like Calendly and Looker).
I’m Colin, Head of EMEA Engineering at Ashby. I want to share with you how Ashby Engineering is thinking about AI and the changes it brings to how we work. I’m going to assume you’re an engineer.
Our thesis is that the cost of writing code is heading towards zero. The cost of producing meaningful software is not. AI isn’t coming for our jobs, it’s coming for the mechanical parts of them: syntax, glue code, and the tip-taps of keystrokes. The parts that are less interesting, less challenging.
The part that matters for engineers - your judgment, your taste, your understanding of our customers - is getting more important, not less. Your value as an engineer was always weighted in your judgment. Every efficiency gain in producing high-quality code shifted the role further in that direction. AI will be a larger shift than we’ve seen before.
That shift is already here. “Almost all my PRs are entirely AI-written now. I implemented an entire data ingestion via AI… It's ~40 PRs” - Tom, one of our engineers.
Like any emerging technology, the industry is figuring out how to use AI effectively to build software. When to trust it, when to override it, and what needs to change in our systems so that "move fast" doesn't become "move recklessly." It's a shared mental model, and I expect it to evolve as we learn.
The Ground Rules
As we use LLMs more and the world around us shifts, we believe there are two ground rules:
Empathy cannot be replaced by AI
You are responsible for what you ship
Empathy Cannot Be Replaced by AI
Building products is a human endeavor. LLMs do not have taste. They do not know our customers. They cannot feel or understand the frustration of using a bad product or the delight of using an exceptional one. That still requires judgment, and, in a world where building a functional product is insanely fast, the ability to build a great one is even more important.
We also value individual focus, so when we collaborate, it’s important we do it effectively. We don’t do mindless standups. We don’t do planning poker. We do write documents for our colleagues to read and understand. We do ask for help with reviewing changes.
Empathy means remembering to write these documents for the humans who will read them. LLMs can help with writing. But, without guidance, LLMs will write documents that seem convincing yet are hard for humans to read, full of unimportant details, and lacking joy and wisdom. Here’s an excerpt of a PR description I had an LLM write:
1Added .github/workflows/pr-relevant-test-coverage.yml:
2 - Triggers on pull_request (excluding master) and
3 workflow_dispatch with pr_number.
4 - Resolves PR number, collects changed files, and asks
5 Claude to output up to 15 relevant test files.
This is all information that we can trivially figure out from reading the PR, and the full description was close to 30 lines. The most useful line still missed the mark:
1Coverage is intentionally not full-suite coverage; it
2reflects only Claude-selected relevant tests against
3changed files.
Why? Why does this not run full-suite coverage? This description does not respect our colleague’s time. It is devoid of empathy for us as reviewers and future maintainers of this code.
1Coverage is intentionally not full-suite coverage. The
2full suite with coverage takes hours to run. We are
3using this to give guidance to engineers on where risks
4lie.
Remember what empowers our colleagues to help us. Don’t cede writing documents for humans to LLMs.
You are responsible for what you ship
LLMs can be wonderfully wrong. Confidently incorrect. Inexplicably careless. The biggest risk with AI isn’t that it’s wrong. It’s that it sounds right.
“I didn’t mean to remove the tar-stream package - it was an accidental casualty when I was editing backend/package.json…” - Claude Code
You are responsible for what you ship. Whether every line is handwritten or an LLM generated the entire PR. You are responsible for understanding what the code does, why it does it, and what happens when it breaks.
As we use LLMs more, skepticism has to increase, not decrease. Ask for alternatives. Ask for edge cases. Ask it to critique itself. Understand the reasoning before accepting the output.
Think More, Think Harder
We must think more - and think harder than before. LLMs make it easy to no-brain your way through something. Resist that urge. Stay vigilant. It is easy to throw an issue at an LLM, have the PR description auto-generated, get the LLM to write the tests, and throw the PR out for review… all whilst fixing the entirely wrong issue or building a subpar solution.
A particularly nefarious manifestation of this is running lots of agents in parallel on disparate tasks. This is multi-tasking on steroids. Multitasking is ineffective because the human brain can’t focus on multiple high-level tasks simultaneously. It may feel super productive to have five agents working on five issues and flicking between them all, but are you really making your best decisions? Are you able to think deeply about the guidance each agent needs? Do you understand what is being built?
The current hype cycle often emphasizes quantity and velocity above all else, while ignoring quality and ingenuity, or with the promise that somehow these outcomes will follow. At Ashby, we are not succumbing to this pressure. It’s a myopic view of the world where everything can and should be shortcutted. Shortcuts always existed, and many of them reduce the quality and ingenuity of our work:
These external quotes reflect our own journey to success. Before AI, we could have always moved faster: we could have outsourced work to contractors, we could have built features instead of building blocks, we could have launched earlier. But the hours we spent hiring quality folks instead of outsourcing, thinking of abstractions instead of coding, and being patient with our product were often more impactful than the alternative. Thinking deeply is part of why we’re a successful startup today, and we’re not stopping.
Specs are Still for Humans
One of the shifts we’re seeing is the intention to feed specs to LLMs.We've always valued specs. They derisk development and ensure alignment. LLMs also benefit from the context that specs can provide.
However, what a human needs from a spec and what an LLM needs from a spec are different. As humans, we need something that is mindful of our time, engages us as readers, and focuses our attention on the decisions that matter. E.g., something that tells us why you’ve decided to use Redis instead of Postgres vs a document detailing every single possible value for a new enum.
We need something empathetic to us.
We must continue writing specs for humans. Specs are focused on the expensive-to-change decisions. Specs reduce the risk that we build the wrong thing. They identify the abstractions that we’re going to need. For example, I was talking with one of our engineers about a requirement to perform an action on potentially millions of forms, and our framework doesn’t support that. Do they create a one-off implementation for their use case or figure out how to improve the bulk action building block? That’s the kind of decision we need to capture. It completely changes the implementation. It affects everyone else. Get it right, and we’ve created leverage for the next person.
Specs are written for humans. An LLM might consume them as useful additional context.
How to Think About LLMs
We’ve set the ground rules and discussed how we want to interact as humans. Now: how we think about operating with LLMs.
There’s a lot of great material out there that gives an introduction to how LLMs work (this post by Sam Rose is a good one).
First, LLMs are not lazy. They will produce code. And keep going. They won’t stop and ask, “Should I create an abstraction for this?” They’re great at summarizing swathes of information. They’re not novel thinkers. They won’t make the mental leaps that allow you to simplify something and delete thousands of lines of code.
A simple model I use is to think of the LLM as a set of dice, not the hyped superintelligence.
Some problems LLMs are good at, and you don’t need to roll a high score for. They’re great at summarizing documents, finding patterns, and continuing them.
Some problems they’re terrible at. You’ll never get enough sixes in a row. Counting the number of r's in “strawberry”, multiplying large numbers, or figuring out which direction you're facing after a series of turns. These feel like they should be easy, but they require a kind of precision that dice just can't reliably give you.
And then there are ways to load the dice to tip the odds in your favor, like giving them an example of what good looks like.
With that model in mind, here's how working with LLMs plays out in practice.
Two Modes of Working With AI
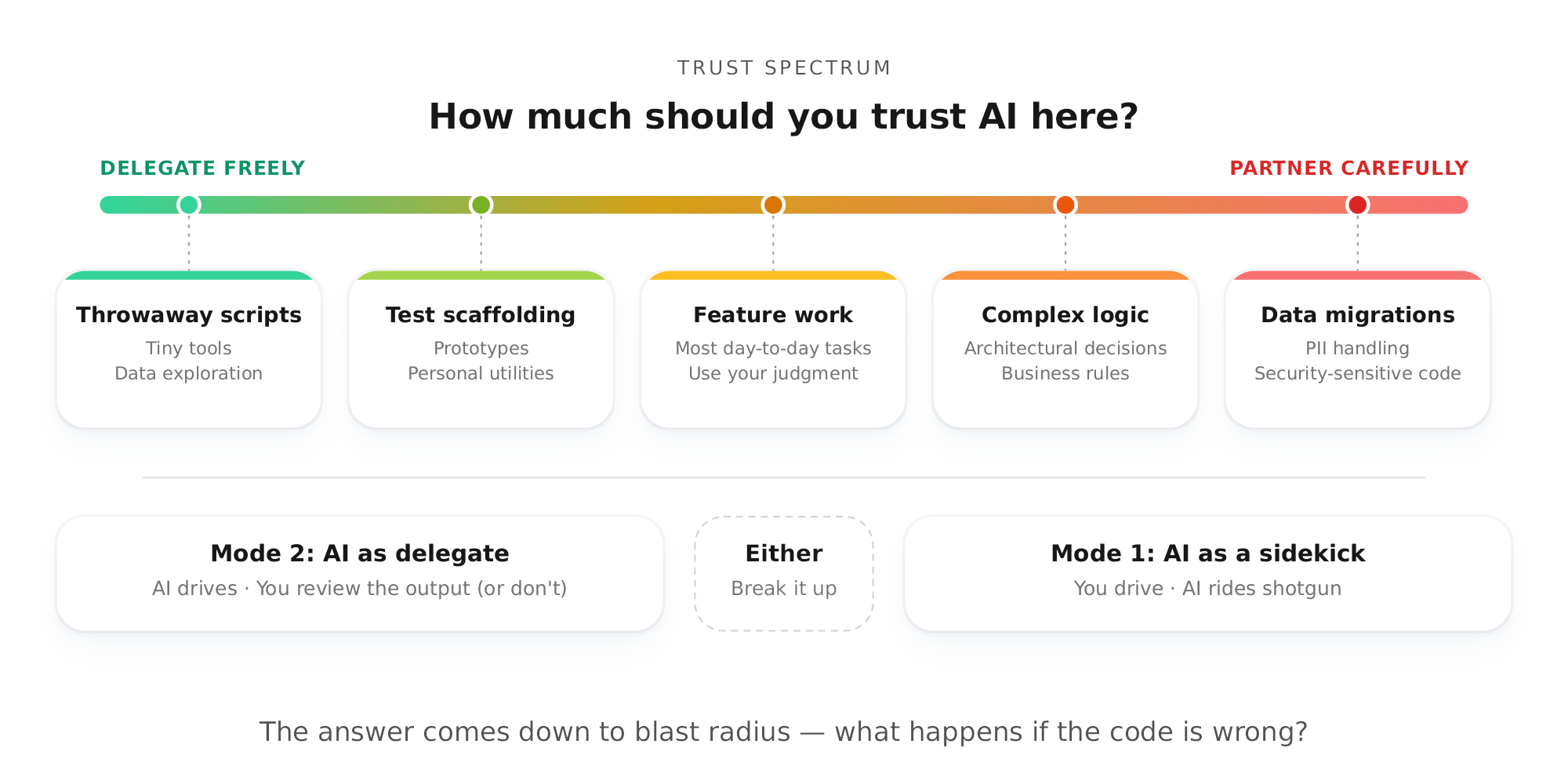
I see two distinct ways to work with LLMs: as a sidekick or as a delegate. Recognizing which mode you're in and which you should be in is the key skill.
Default to sidekick mode. You’re using AI to explore the codebase, find and digest large amounts of information, and implement the detailed specs you’ve written. You are making most of the decisions.
This is the mode for anything high-risk: database migrations, candidate data handling, security-sensitive code, and architectural decisions. These are the places where “looks right” isn’t good enough. You need to be in the driver's seat.
Switch to delegate mode when the blast radius is small. You review the output - or sometimes you don't. Prototyping, local tools, and operations tools are great candidates here. You can move fast because the cost of failure is low.
Most engineers will over-delegate at first. Then they’ll over-correct and under-delegate. The question is never "should I use AI?" - it's "how much should I trust it here?" Think about what happens if the code is wrong. Is it embarrassing? Expensive? Existential?
Blending between the two will be common. That’s where your judgment matters, and where breaking up the task pays off. You might start off by having the LLM build the scaffolding of the new feature you’re working on, hand-write some SQL queries, and finally jump back to full delegation for writing a few unit tests.
How We’re Using AI Today
We’re actively encouraging engineers to use AI tools to support their work. We’re doing this through education, workshops, pairing, and generous token budgets. We do not mandate the use of AI or measure token usage. Our belief is that doing so encourages slop.
As writing code gets cheaper, safety becomes more important. Safety has to be built into the infrastructure, not imposed as discipline. We think of safety using a Swiss Cheese model. Every layer has holes, but the holes are in different places. Tests catch what review misses, feature flags catch what tests miss, and observability catches what slipped past everything else.
We start by giving all our engineers access to AI code generation tools. There’s an easy path for engineers to request access to Cursor, Claude Max, Codex, and various agent frameworks, with no token limits in Cursor.
We’re also using linters, DangerJS, and AI to help with code review. Many common issues are caught by our linters and Danger rules, and our team actively invests in expanding these automated checks. We use third-party tools like CodeRabbit to do a first pass before a human. We’ve also built our own code review tool focused on finding edge-case bugs that are hard to deal with in production. We find it's better at this than third-party tools because we can use more tokens and tightly control the context.
We also provide shared infrastructure for AI tools (both third-party and built in-house) to thrive. Our skill files live in our repos, and our team contributes to them weekly. Engineers have access to a repo that clones the Git metadata from our main repo into a SQLite DB. All the issues, pull requests, and comments are all there. This enables engineers and in-house LLM tools to more rapidly answer questions like “Has anyone seen a bug like this before? What was the resolution?” — it’s faster and more accurate than interacting via the GitHub API.
We also use AI to improve our collaboration with other departments. We’ve trained an internal model to automatically triage customer issues and send them to the right product team. We have an automation that tasks Claude Code with reviewing incoming bugs and producing a report on likely causes, people to consult, and avenues for further exploration. In some cases, this has helped Support fix issues within ten minutes instead of hours. For example, there was a substitution tag missing in a user’s offer letter template - the kind of issue that engineers often have to stare at for far too long. Claude Code spotted it straight away.
What's Next
We’re continuing to invest in DevEx and tooling to ensure AI generates high-quality code while placing less burden on humans. Conceptually, here’s how we’re thinking about it.
Change Review
At Ashby, we already review code changes. Our reviews are fairly broad and cover everything from bug spotting and abstraction opportunities to code documentation. The coming increases in output will outpace our ability to review. We need to be critical of why we review code. We need to make sure we’re spending our review time on the highest value targets.
Humans are bad at catching bugs. Engineers shouldn't spend time thinking about whether someone else has used useMemo correctly in a component. We aren't here to be human linters. Humans shouldn’t spend significant time reviewing each line of another human’s code. Self-review and other tooling (e.g., linting) should handle 90% of that. If you’re reviewing, for example, an automated refactor to extract a function in 2026, we’ve failed.
So what are we here to review?
Does the change make sense?
What are the high-risk areas? How can we reduce those risks?
What are the performance characteristics?
Are the abstractions sensible? Are we abstracting enough?
That last point on sensible abstractions deserves emphasis. LLMs are biased toward generating new code rather than reusing what exists. Left unchecked, they'll build you a codebase that works but that no one can navigate. LLMs don’t care if the code they’ve produced is complicated. Pushing toward simplicity is now one of the most valuable things a reviewer can do. This happened to me on a side project - there were two “interface modes,” and the LLM had created copies of everything in each mode! I only realized when I fixed the same bug twice.
We’re continuing to invest in this area. There are many interesting avenues to explore and experiment with. Can an LLM give a first-pass design critique for new UIs? Can they do a valuable critique of a spec?
Automatic Verification
For years, writing code has been the expensive part, and testing has been an afterthought. AI has flipped that. Writing is now cheap. Verification is the bottleneck, and our investment needs to follow.
We already have unit tests and end-to-end tests. Our QA team has created skills files that describe how to consistently and sustainably create these tests whilst avoiding flaky tests (which can quickly erode confidence in end-to-end tests). Engineers are now writing end-to-end tests using Playwright. 65 new test cases were created over the past four weeks; 70% were contributed by people outside the QA team.
We need more and better tests: fuzz tests and frontend unit tests. Static analysis is once again more relevant. We'll need more AI reviewing AI. Automated review focused on performance, PII handling, error handling, and security. The challenge will be managing the noise so humans can focus on the decisions that matter. This is an area we will be investing in.
The good news is that the cost of writing tests is also going to zero. We humans have to keep our brains engaged to make sure they’re good tests.
Closing Thoughts
Our codebase has a new audience. Every pattern, every name, every module boundary is now read by LLMs as well as humans - and LLMs take what they find literally. A messy codebase doesn't just slow down your colleagues anymore; it degrades every piece of AI-generated code that touches it. Code quality has always mattered. Now it compounds.
If you feel some resistance to AI generating code, I get it. But think about what you actually enjoy - is it typing the code, or is it the moment the right abstraction clicks into place? AI takes the first part. The second part is about to matter more than ever. And you can't build the right abstraction if you don’t understand the problem and who you're solving it for.
That makes customer understanding a core engineering skill. So, our engineers now spend more time doing other things. Watching user session replays. Watching customer interviews. Talking to our internal users. Reading support conversations. Engineers who understand the problem space waste less time building the wrong thing and make higher-quality, independent decisions. Implementation speed becomes a multiplier on sound judgment - and AI is about to make order-taking teams obsolete while making teams like ours more powerful.
Our engineers are well-positioned for this. We didn't hire them solely because they’re good technically. We hired them because they’re product-minded, good communicators, and capable of sound judgment. The leverage available to a single engineer right now is absurd. And it's only going up.
Sound good? We’re hiring for fully remote engineers across Europe and the Americas.
Share this post
Subscribe to Updates
Ashby products are trusted by recruiting teams at fast growing companies.